Architecture
Monitoring Cloud Servers with QRadar
Cloud computing is an inevitable upward trend. Companies are looking for all the benefits cloud computing, such as cost effectiveness and scalability, but they may be neglecting the need of event monitoring in a cloud environment.
Configuring a SIEM solution to collect events from servers in a cloud environment may be simpler than you think. Cloud servers are still servers, meaning that they produce logs and events as any in-house server. In this post we will be discussing few strategies and architectures to consider when planning a QRadar implementation with servers in the cloud.
The first scenario is when you have just few servers in the cloud (less than 15% of your environment, or less than 500EPS coming from the cloud). A easy approach for this scenario can be simply configuring your cloud servers to send logs to your existing in-house QRadar collector (Figure 1). This can be accomplished by using a VPN between your cloud environment and your datacentre, or by configuring your firewalls to allow your cloud servers to send logs directly to your in-house collector. The benefits in this case are the fact that is a very easy setup and there’s virtually no costs. The downside on this design is that if your server generate a high number of events, your firewall/VPN could be overloaded.
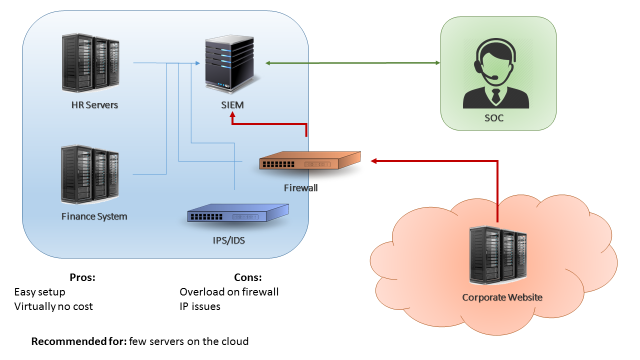
The second scenario is when you have a substantial amount of servers in the cloud (between 30%-40% of your environment, or less than 5000 EPS). In this case, if you try to send all your events directly through a firewall or VPN you may overload the border network devices of your environment. The recommended approach in this case would be implementing a virtual collector/processor in your cloud environment (Figure 2). The cloud servers would send logs to your virtual collector/processor, which will parse the data locally and compress it before sending to the in-house SIEM collector. This architecture benefits from the fact that you will have an increased EPS capacity. Also, if your VPN dies or if the network is unstable you don’t lose events due to the fact the collector buffers the logs locally. In other hand, this architecture will have an extra cost (the additional collector) and, even with the traffic being compressed, it still may affect your firewall/VPN performance in case you’re monitoring a large quantity of servers.

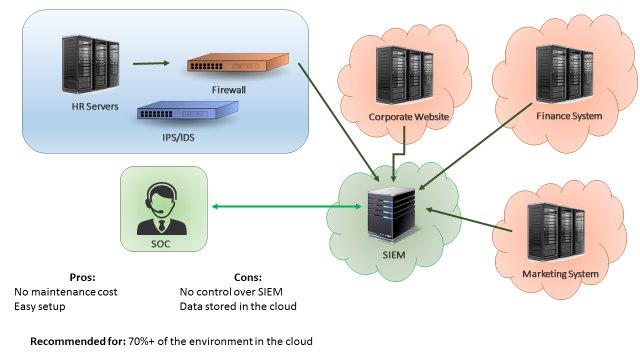
The third scenario is when most of your servers are in the cloud. In this case, a good approach would be having QRadar collectors (or even your whole QRadar infrastructure) deployed on the cloud, as seen on Figure 3. In this way, your border network devices will not be overloaded by logs sent from cloud servers to your internal SIEM. A similar approach would be having “QRadar as service”, which is a service from IBM where all the SIEM infrastructure is taken care by the IBM team. The advantages of having SIEM as a service is that you don’t need to worry about the SIEM maintenance and there’s little to none setup effort. The disadvantages is that your data will be stored in the IBM cloud environment, which for some companies may not be adequate.
Those are the three most common approaches when monitoring cloud servers with a SIEM solution. It is important to remember that each case is a case, meaning that each company should analyse their current and future environment before designing a SIEM implementation. You may find that a combination of the presented approaches may suit best your needs. The most important thing is remembering that monitoring servers in the cloud is as important as monitoring in-house servers.
QRadar and Big Data
Today I was reading about the new QRadar integration with the IBM BigData solution. Instead of writing down here, I decided to share with you guys a very nice video that summarize the benefits of this integration.
(Part 1) QRadar Basics and Big Data
(Part 2) QRadar BigData Extension:
I hope you guys enjoy the videos. You can also check more from the author in his youtube channel.
Centralized vs. Distributed collecting
One of the main questions when designing the architecture of a QRadar environment is using a centralized (with or without clustering) or a distributed deployment. It means, should we create a cluster of QRadar in a specific network or should we distribute our collectors across the networks? As usual, the answer is: Depends.
The following pictures summarize the benefits and cons of the both cases.
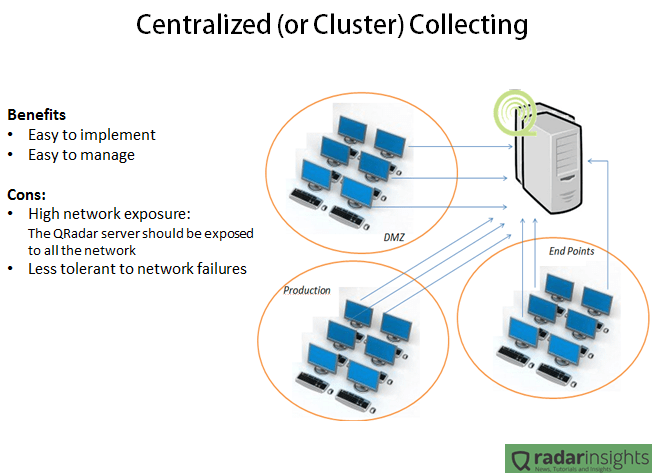
In the Centralized scenario, all the servers and collectors are in the same network. It makes the deployment and management way easier since we have just one point of maintenance and one point to “care about”, and it is very important especially when we have a geographically spread environment. But having all the SIEM solution in one network means that all the environment will need to connect to the cluster. In other words, the firewalls will allow traffic between the QRadar cluster and any server. Considering that some collection methods involves windows authentications, it means that if someone get access to the QRadar cluster network, the person will have access to any device on the network. Another bad point of this kind of deployment is the network failure tolerance. Lets say that the router in the border of the QRadar network goes down, all the log collection will be lost.

The distributed collection usually takes more time (and money) to implement and requires more time/resources to maintain, since the appliances will be distributed physically and logically. But the advantages are clear. With a distributed deployment the main QRadar console will have access only to its’ collectors, and nothing more. It means that if someone get access to the main SIEM network, the person will be able only to send packets to very specific IPs (collectors), and since the QRadar collectors are completely hardened, the security risk involved on this deployment is very low. Another benefit of the distributed deployment is the network failure tolerance. Considering the same case of a broken router in the QRadar console network, in this case the collectors will not have connection with the main console and will buffer the logs. After the network connectivity being restored, the logs will be synchronized with the main console.
As you guys noticed, the Distributed deployment can bring some good advantages compared with the Centralized one. But each company is a different case. Is up to you as an architect decide which deployment will fit your client need.
Do you have any suggestion or comment? Drop us a line in the comments!
