Centralized vs. Distributed collecting
One of the main questions when designing the architecture of a QRadar environment is using a centralized (with or without clustering) or a distributed deployment. It means, should we create a cluster of QRadar in a specific network or should we distribute our collectors across the networks? As usual, the answer is: Depends.
The following pictures summarize the benefits and cons of the both cases.
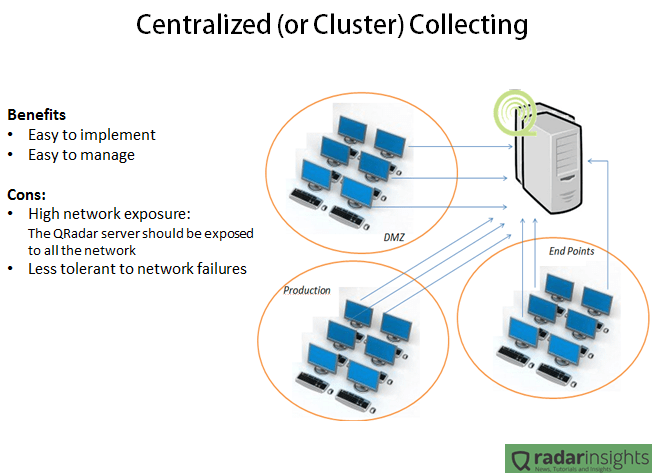
In the Centralized scenario, all the servers and collectors are in the same network. It makes the deployment and management way easier since we have just one point of maintenance and one point to “care about”, and it is very important especially when we have a geographically spread environment. But having all the SIEM solution in one network means that all the environment will need to connect to the cluster. In other words, the firewalls will allow traffic between the QRadar cluster and any server. Considering that some collection methods involves windows authentications, it means that if someone get access to the QRadar cluster network, the person will have access to any device on the network. Another bad point of this kind of deployment is the network failure tolerance. Lets say that the router in the border of the QRadar network goes down, all the log collection will be lost.

The distributed collection usually takes more time (and money) to implement and requires more time/resources to maintain, since the appliances will be distributed physically and logically. But the advantages are clear. With a distributed deployment the main QRadar console will have access only to its’ collectors, and nothing more. It means that if someone get access to the main SIEM network, the person will be able only to send packets to very specific IPs (collectors), and since the QRadar collectors are completely hardened, the security risk involved on this deployment is very low. Another benefit of the distributed deployment is the network failure tolerance. Considering the same case of a broken router in the QRadar console network, in this case the collectors will not have connection with the main console and will buffer the logs. After the network connectivity being restored, the logs will be synchronized with the main console.
As you guys noticed, the Distributed deployment can bring some good advantages compared with the Centralized one. But each company is a different case. Is up to you as an architect decide which deployment will fit your client need.
Do you have any suggestion or comment? Drop us a line in the comments!

April 29, 2014 at 1:50 pm
Hi,
it’s a great post and I totally agree that it is a matter of trade-off between costs, security, maintainability and performances. Regarding the performances, do you have any figures on network bandwidth used between QRadar components and network compression ? Do you know how many Event Collectors (EC1501) an event processor is able to handle ?
May 9, 2014 at 2:20 pm
Hi Javier,
I couldn’t find this information on the documentation so I can’t give you a correct answer. I suggest you to contact the IBM support for this question. But just to have an average of bandwidth, you can calculate your EPS and multiply it by 400. You will get the bytes per second being transmitted between your logsources and your collectors.
October 3, 2014 at 6:35 am
[…] Centralized vs. Distributed collecting […]